DICOM organization
Nipoppy docs are moving
Nipoppy is undergoing a major refactor to move from scripts to a command-line interface (CLI) and Python API. The new documentation website (work in progress) can be found at https://nipoppy.readthedocs.io/.
If you are using the (soon-to-be legacy) scripts from Nipoppy 0.1.0, this is still the correct place to be. But we encourage you to check out the new website!
Objective
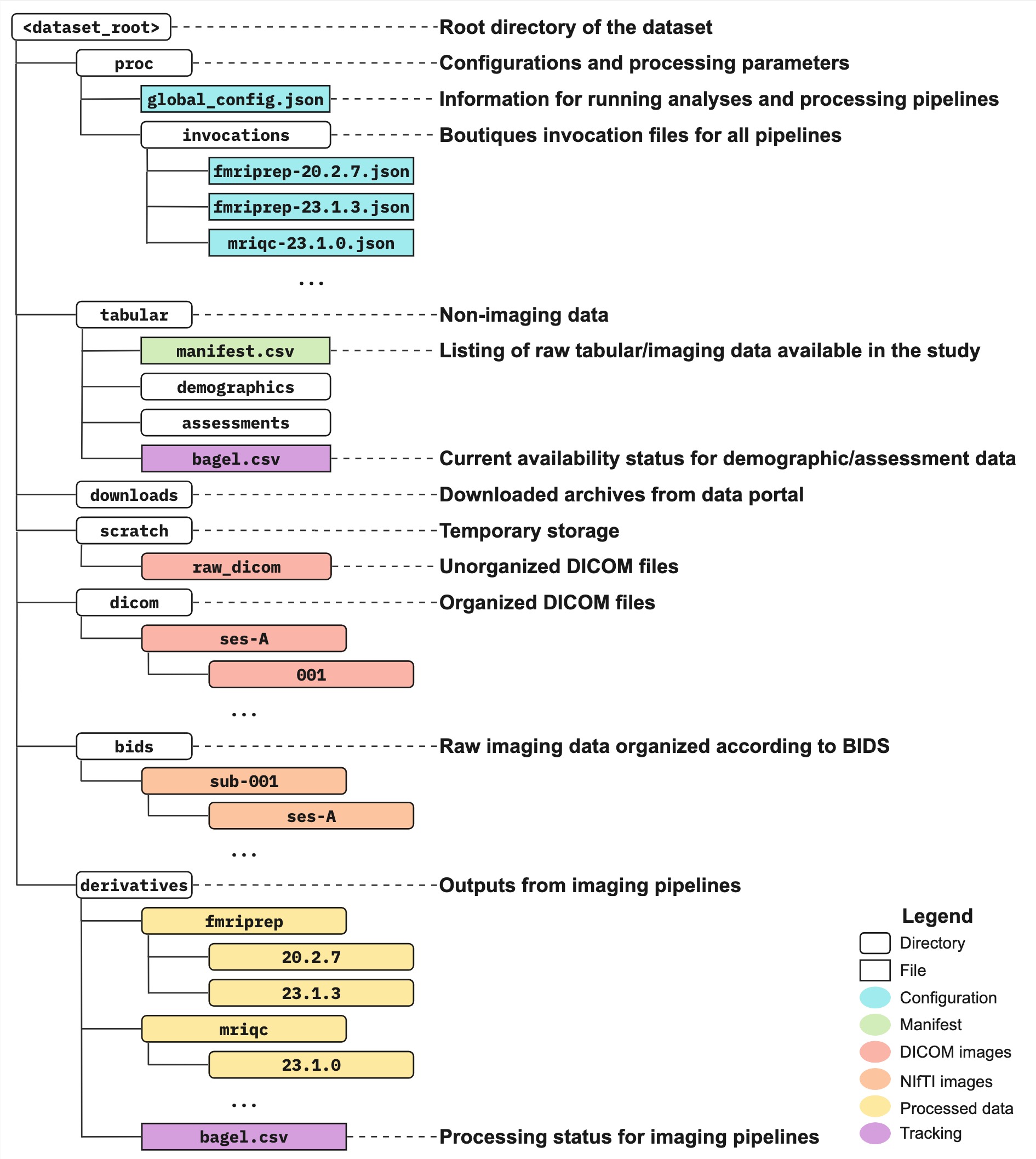
This is a dataset-specific process and needs to be customized based on local scanner DICOM dumps and file naming. This organization should produce, for a given session, participant specific dicom dirs. Each of these participant-dir contains a flat list of dicoms for the participant for all available imaging modalities and scan protocols. The manifest is used to determine which new subject-session pairs need to be processed, and a doughnut.csv file is used to track the status for the DICOM reorganization and BIDS conversion steps.
Key directories and files
<DATASET_ROOT>/tabular/manifest.csv<DATASET_ROOT>/downloads<DATASET_ROOT>/scratch/raw_dicom<DATASET_ROOT>/scratch/raw_dicom/doughnut.csv<DATASET_ROOT>/dicom
Procedure
- Run
nipoppy/workflow/make_doughnut.pyto updatedoughnut.csvbased on the manifest. It will add new rows for any subject-session pair not already in the file.- To create the
doughnut.csvfor the first time, use the--emptyargument. If processing has been done without updatingdoughnut.csv, use--regenerateto update it based on new files in the dataset.
- To create the
Note
The doughnut.csv file is used to track the multi-step conversion of raw DICOMs to BIDS: whether raw DICOMs have been downloaded to disk, re-organized into a directory structure accepted by HeuDiConv, and converted to BIDS. This file is updated automatically by scripts in workflow/dicom_org and workflow/bids_conv. Backups are created in case it is needed to revert to a previous version: they can be found in <DATASET_ROOT>/scratch/raw_dicom/.doughnuts.
Here is a sample doughnut.csv file:
| participant_id | session | participant_dicom_dir | dicom_id | bids_id | downloaded | organized | converted |
|---|---|---|---|---|---|---|---|
| 001 | ses-01 | MyStudy_001_2021 | sub-001 | sub-001 | True | True | True |
| 001 | ses-02 | MyStudy_001_2022 | sub-001 | sub-001 | True | False | False |
| 002 | ses-01 | MyStudy_002_2021 | sub-002 | sub-002 | True | True | False |
| 002 | ses-03 | MyStudy_002_2024 | sub-002 | sub-002 | False | False | False |
- Download DICOM dumps (e.g. ZIPs / tarballs) in the
<DATASET_ROOT>/downloadsdirectory. Different visits (i.e. sessions) must be downloaded in separate sub-directories and ideally named as listed in theglobal_configs.json. The DICOM download and extraction process is highly dataset-dependent, and we recommend using custom scripts to automate it as much as possible. - Extract (and rename if needed) all participants into
<DATASET_ROOT>/scratch/raw_dicomseparately for each visit (i.e. session).- At this point, the
doughnut.csvshould have been updated to reflect the new downloads (downloadedcolumn set toTruewhere appropriate). We recommend doing this in the download script (i.e. in Step 2), butworkflow/make_doughnut.pycan also be run with the--regenerateflag to search for the expected files (this can be very slow!).
- At this point, the
Note
IMPORTANT: the participant-level directory names should match participant_ids in the manifest.csv. It is recommended to use participant_id naming format to exclude any non-alphanumeric chacaters (e.g. "-" or "_"). If your participant_id does contain these characters, it is still recommended to remove them from the participant-level DICOM directory names (e.g., QPN_001 --> QPN001).
Note
It is okay for the participant directory to have messy internal subdir tree with DICOMs from multiple modalities. (See data org schematic for details). The run script will search and validate all available DICOM files automatically.
{kind=link}
- Run
nipoppy/workflow/dicom_org/run_dicom_org.pyto:- Search: Find all the DICOMs inside the participant directory.
- Validate: Excludes certain individual dicom files that are invalid or contain scanner-derived data not compatible with BIDS conversion. Enabled by default, disable by passing
--skip_dcm_check. - Symlink (default) or copy: Creates symlinks from
raw_dicom/to the<DATASET_ROOT>/dicom, where all participant specific dicoms are in a flat list. The symlinks are relative so that they are preserved in containers. Disable by passing--no_symlink. - Update status: if successful, set the
organizedcolumn toTrueindoughnut.csv.
Sample cmd:
python nipoppy/workflow/dicom_org/run_dicom_org.py \ --global_config <global_config_file> \ --session_id <session_id> \