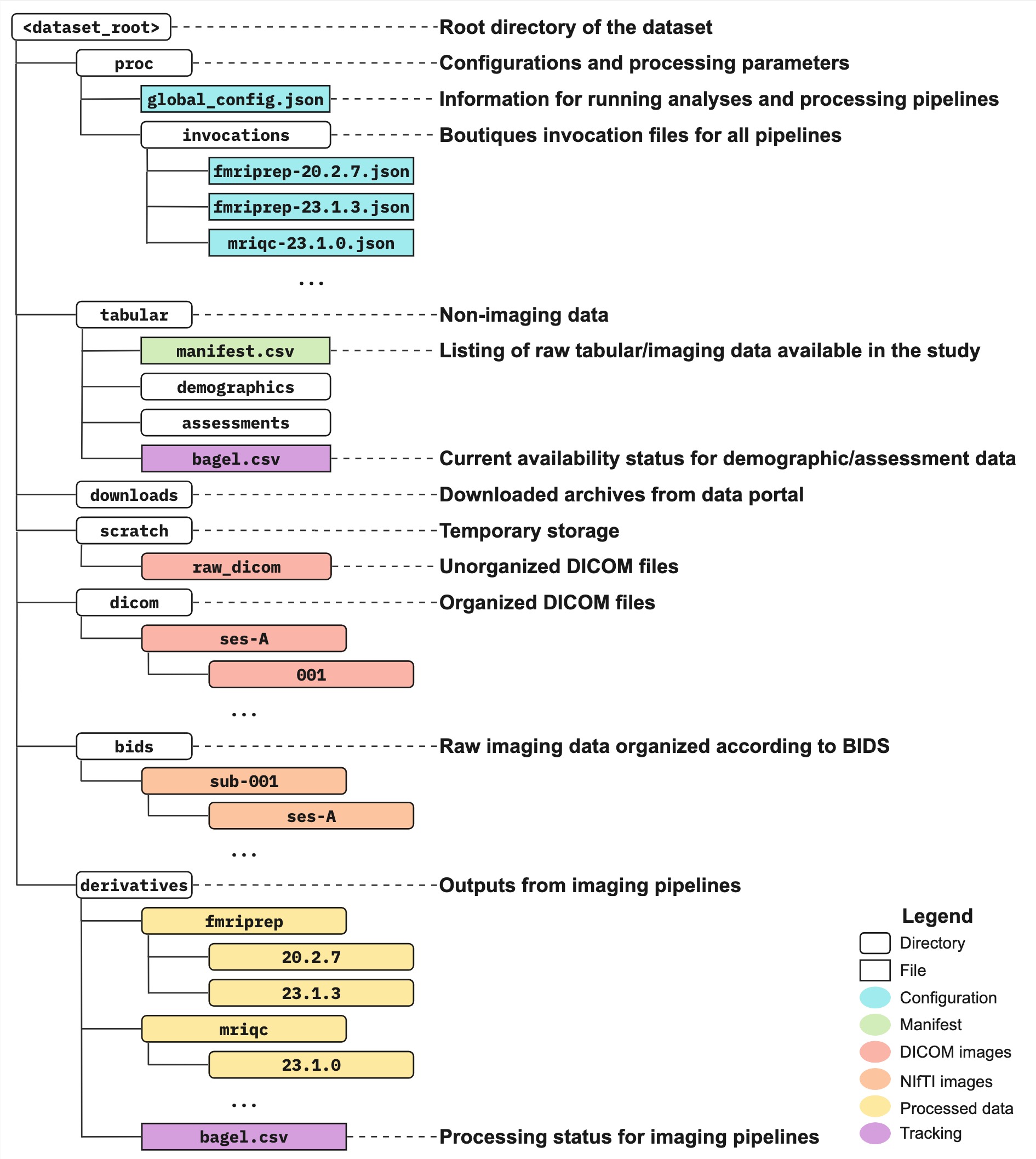
Data organization
Nipoppy docs are moving
Nipoppy is undergoing a major refactor to move from scripts to a command-line interface (CLI) and Python API. The new documentation website (work in progress) can be found at https://nipoppy.readthedocs.io/.
If you are using the (soon-to-be legacy) scripts from Nipoppy 0.1.0, this is still the correct place to be. But we encourage you to check out the new website!
Data organization
An Nipoppy dataset consists of a specific directory structure to organize MRI and tabular data.
Directories:
tabular- contains
manifest.csv demographics: contains demographic data (e.g. age, sex)assessments: contains clinical assessments (e.g. MoCA)
- contains
downloads: data dumps from remote data-stores (e.g. LONI)scratch: space for un-organized data and wranglingdicom: participant-level dicom dirsbids: BIDS formatted datasetderivatives: output of processing pipelines (e.g. fmriprep, mriqc)proc: space for config and log files of the processing pipelinesbackups: data backup space (tars)releases: data releases (symlinks)